化学信息学中的立体化学
Comment由于大多数化学信息学的应用模型(如 QSAR)都不考虑化合物的手性信息,因此大家在构建模型时也常常有意或无意地忽视它,甚至在建模之前直接将化合物的手性信息去掉。该过程无可厚非,毕竟既然对应异构体的分子指纹如果是一样的,若其活性也一样就没有必要作为重复数据出现在训练或测试集中,若其活性有很大
区别,则不仅无法利用,反而增加模型训练的难度,试想同一个 X 怎么能得到两个 Y 呢?
随着数据的增大以及我们对手性分子处理技术的增加,使得我们在建部分模型时需要考虑到手性,比如逆合成分析中,若目标产物是个 R 构型的化合物,而给出的产物只能合成 S 构型的产物,那么这样的模型显然是欠佳的。我们如何处理化合物的手性呢?
SMILES 中的手性表达
其实 SMILES 本身是支持手性的,在表达式中 @ 和 @@ 分别用来表示对映异构情况。但大家可能只知道其分别表示一对对应的手性分子,却不知到底代表什么,与教科书定义的 R/S 构型又有什么区别。
根据 DayLight 给出的“官方文档”,@ 与 @@ 分别表示“顺时针”与“逆时针”
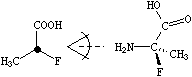
上图表示的是 alpha-氟丙氨酸 (欢迎纠错),我们可以用 N[C@](C)(F)C(=O)O 表示,这个 SMILES 可以这样理解,从 N0 原子的角度看手性碳原子 [C@],C2(甲基)、F3 以及 C4(羧基)的原子呈逆时针排列。
教科书中的手性表达
用我们化学知识判断,甲基应该放在屏幕后面,F N C(羧基) 三个原子呈顺时针排列,所以是 R 构型。这套规则一般称为 CIP 规则,由于被 IUPAC 官方认可,才使得我们在教科书中也这样学。
CIP 虽然有点反人类,要描述一个原子的手性,非得先排个序,但其好处非常明显,一个化合物结构是固定的,因此排序是固定的,也因此 R/S 也是固定的,于是我们也称之为“绝对手性”。再回过头看 SMILES 中的表达,不难发现它还真的叫“相对手性”,因为这个手性原子到底应该是顺时针还是逆时针,取决于这些原子在 SMILES 中的排序,比如我颠倒 C 和 F 的位置,则该分子就可表示为 N[C@@](F)(C)C(=O)O。这也是 SMILES 让人爱之恨之的特性–不唯一,其手性是靠手性中心 C 原子的顺逆属性以及其周边原子的出场顺序共同决定。
以 RDKit 为例的化学信息学表达
手性可以用 SMILES 中的顺逆时针表达,也可以用 R/S 表达,RDKit 是怎么做的呢?。其实它记录的是手性原子是与周边原子是顺时针还是逆时针关系,这样无论是读 SMILES 还是写 SMILES 都非常方便。
还是以刚刚 N[C@](C)(F)C(=O)O 这个化合物为例,在 RDKit 中的描述是这样的:
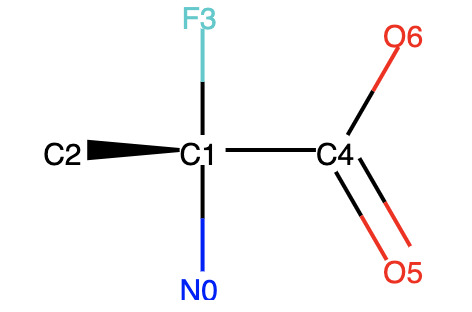
需要注意的是,RDKit 会自动为每个原子一个索引(id),其索引顺序就是 SMILES 的输入顺序,因此它就可以知道 C2 F3 C4 三个原子的顺序就是 C1 的标记“逆时针”(图画的比较丑,需要点空间想象力才能看出是逆时针,注意是以 N0 的视角看,而不是像 CIP 规则一样把 N0 放到屏幕后面去)。
如何将相对旋转反向转化为 R/S 构型
看 RDKit 是怎么计算化合物的绝对手性的
毕竟 R/S 是根据 CIP 定义的,所以要计算化合物的绝对手性,仍然需要知道邻边的“排序”。具体排序的算法可以参考 RDKit 源码,我们可以直接使用 RDKit 提供的接口获取原子的排序。1
2
3
4
5
6
7
8
9
10
11m = Chem.MolFromSmiles('N[C@](C)(F)C(=O)O')
for atom in m.GetAtoms():
print(atom.GetProp('_CIPRank'))
# Output:
3
2
0
6
1
5
4
不难看出,N0 C2 F3 C4 四个原子对应的排序是 3 0 6 1,即 F3 > N0 > C4 > C2。 回顾下,我们已知的是 N1 看 C2 F3 C4 呈逆时针,现在要想办法将这个逆时针信息与已知的四个原子排序联系起来。为了简化,我们以后这样定义数组(N1 C2 F3 C4)= @
首先,根据 CIP,我们要把 C2 放在屏幕后,看 F3 N0 C4 的顺序,要知道这个描述和我们之前说的“化学信息学”描述有点不一样,怎么转化呢?我们可以这样想:
- 如果我们知道 C2 看 F3 N0 C4 的顺序,我是否能知道 R/S ?答案是可以。C2 看 F3 N0 C4 的顺序,和 CIP 指导我们的看法正好相反,CIP 把 C2 藏在背面,然后从屏幕正面看,若顺时针为 R。所以 (C2 F3 N0 C4)={R:@,S:@@}。
- 这里先用上帝之角再做一件事,如果我们已知 F3 N0 C4 C2 的顺序,那么知道 C2 F3 N0 C4 就很方便,原因是这两个顺序差别是固定的,所以这两者必然不是相同就是相反,这里先卖个关子。之所以这样做,因为 F3 N0 C4 C2 正是刚刚求 CIP 排序得到的结果。所以最终的问题变成了,已知(N1 C2 F3 C4)= @ 求 (F3 N0 C4 C2)= ?
虽然这节没有给出具体如何计算得到 R/S,但基本清晰了我们可以将原来化学信息学的表述方法,通过计算邻边原子的 CIP 排序值转化为 R/S,当然我们还需要解决一个问题,这四个数字换位置后,顺逆发生怎样的变化?
排列奇偶性
虽然作为基础知识,似乎这个应该先提,不过笔者认为还是先提出问题再介绍解决思路。
无论化学信息学中的顺时针逆时针表达,还是 R/S 构型表达,都有一个非常有意思的“数学现象”,即任意两个邻原子的位置发生交换,R/S 构型则发生一次交换。从 N[C@](C)(F)C(=O)O这个分子也能看出,如果我把 C2 和 F3 位置调换,要么化合物手性发生变化,要么我需要将 [C@] 改为 [C@@] 以保持绝对手性。即 (N0 C2 F3 C4)= @ 可以得出 (N0 F3 C2 C4)= @@。
所谓排列奇偶性,可以理解为,N0 C2 F3 C4 这个排列发生奇数此交换,则结果交换(@ 变成 @@),如果发生偶数次交换,则结果不变。所以咱可以先解决上面上帝视角的问题,F3 N0 C4 C2 变成 C2 F3 N0 C4 (就是将最小的 C2 挪到最前面去)共发生3次交换(C2冒泡三次),所以结论是, (F3 N0 C4 C2)={R:@@, S:@}
最后我们只要计算(F3 N0 C4 C2)与(N0 C2 F3 C4)的排列发生多少次交换,就可以知道 F3 N0 C4 C2 到底是 @ 还是 @@。从而知道到底是 R 还是 S。
另外其实不难发现最初的顺序一定是从小到大排列的,所以我们简单写个类似冒泡排序的函数并记录交换次数。1
2
3
4
5
6
7
8
9
10
11def countSwap(atoms):
count = 0
flag = 0
while flag == 0:
flag = 1
for i in range(3):
if atoms[i] > atoms[i+1]:
atoms[i], atoms[i+1] = atoms[i+1], atoms[i]
count += 1
flag = 0
return count
于是我们可以算出,原来是 @,通过奇偶性变化得到 @@,所以是 R 构型。
氢原子怎么处理
为了简化,我们不妨直接把 C2 看做是氢原子,保持原来的原子序号不变。毕竟 C2 是最小的原子,所以我们知道它其实仍然是 R 构型。于是 SMILES 会变成 N[C@](F)C(=O)O,可见排序变成了 N0 F3 C4,CIP 排序变成了 F3 N0 C4。和原来相比少掉一个原子,我们是否可以不管呢? 安全起见,我们可以直接把氢原子加进去,找到规律,N0 F3 C4 可以看成是 N0 F3 C4 H,因为 F3 C4 呈逆时针,那么 C4 下一个原子肯定也是逆时针,此时由于 H 排最后,我们可以给它一个“极大值序号”,如 100,这样没有违反前面的前提,即基于 SMILES 的初始排序必须从小到大。而 CIP 排序后的则是 F3 N0 C4 H,这里H排最后是因为 H 序号最小。然后我们依然可以用 countSwap 方法,只是用 100 (或者更大的值)填补 H 的位置即可。
从上面也能看出,其实 H 无论是用信息学方法还是考虑 CIP 排序都是放在最后面的,只是我们必须用一个极大值描述其序号,那么显然我们也可以不考虑它,因为 N0 F3 C4 H 变换到 F3 N0 C4 H 需要交换的次数肯定和不考虑 H 是一样的,因为 H 没有发生位置变化。当然,我们需要把 coutSwap函数里的 3 改成 2。
总结
我们介绍了化学信息学中描述手性的方法,以手性原子前一个原子 A 的视角看手性原子后三个原子 B、C、D 的旋转方向,用 @ 表示逆时针, @@ 表示顺时针。
计算 R/S 构型的算法可以简单总结为四个步骤:
- 用向量(a, b, c, d)(为对应原子的 id 编号)描述初始状态,
- 计算四个邻原子的 CIP 排序,按从大到小排序,如(d, b, c, a)
- 计算原始向量与 CIP 排序向量的奇偶性,若交换次数为奇数,则改变转向。如(d, b, c, a)的状态为 @@。
- 最后得到的 @@ 表示 R 构型, @ 表示 S 构型,具体原因如下:
先将 (d, b, c, a)转化为(a, d, b, c),需要交换 3 次,即原来为 @@ 现在为 @,即逆时针。从 a 的角度看 d, b, c 若是逆时针,则将 a 放到屏幕后,从正面看为顺时针,即为 R 构型。