RetroXpert - 一种基于 EGAT 和 RGN 的逆合成算法
Comment一般说来(单步)逆合成(机器学习)算法主要有三大类,1)主流的是基于反应模板的方法,典型代表是 2018 年发表在 Nature 上的使用蒙特卡洛树以及三个较为传统的深度神经网络方法进行整个逆合成算法,其中最重要的一个神经网络就是根据产物的分子指纹预测一个反应模板,套上该模板即可得到反应物。也有论文称为分子指纹方法。2)最近比较火的是基于语言模型的方法,其中最火的可能就是 Transformer 模型,IBM 就利用该模型做了很多相关工作。3)其实 Attention 和 Transformer 不仅仅可以用于基于序列的方法,也能用在图的方法,于是有了基于图的方法。当然这样分可能也不太好,比如本文就同时使用基于图和基于序列的方法,很多逆合成都将单步逆合成预测分成断键和生成两个环节。
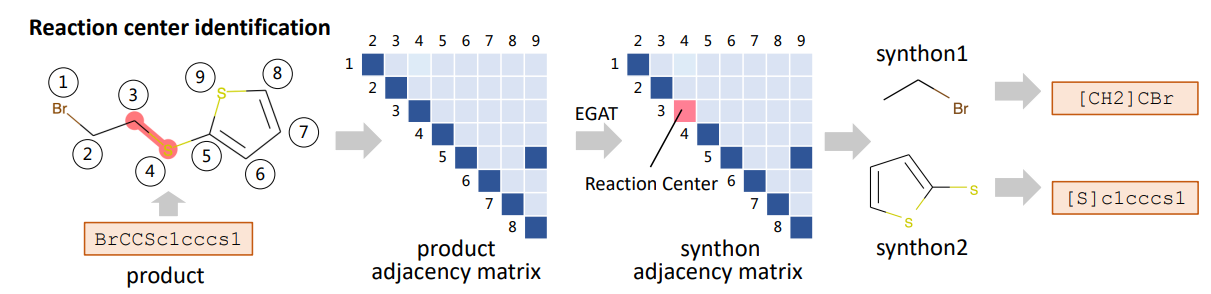
本文主要是介绍一种早在 2020 年就已经发表的一篇同时基于图和序列的逆合成算法 RetroXpert: Decompose Retrosynthesis Prediction like a Chemist 。该算法主要分为两块,第一个是 EGAT(Edge-enhanced Graph Attention Network),该模型利用图注意力神经网络预测产物的断键(Bond Disconnection)位置,有了断键位置就可以将产物变成合成子(Synthon)。第二块是 RGN (Reactant Generation Network),将合成子转化为完整的反应物。
EGAT(Edge-enhanced Graph Attention Network)
第一个模型主要是为了识别逆合成的断键位置,如下图所示,模型的输入是产物分子的图 G(V,E,A),即包含原子的特征 V、键的特征 E 以及产物的邻接矩阵 A,输出的是每个键的断键概率以及“断多少根键”。在预测的时候,得到断键位置即可将产物分子分割为多个合成子。断键的数量可以从 0 到 2(键的数量),0 表示没有断键,如果大于 2 则认为是 2,这里应该是一个经验规则,一般断键数量不会大于 2。
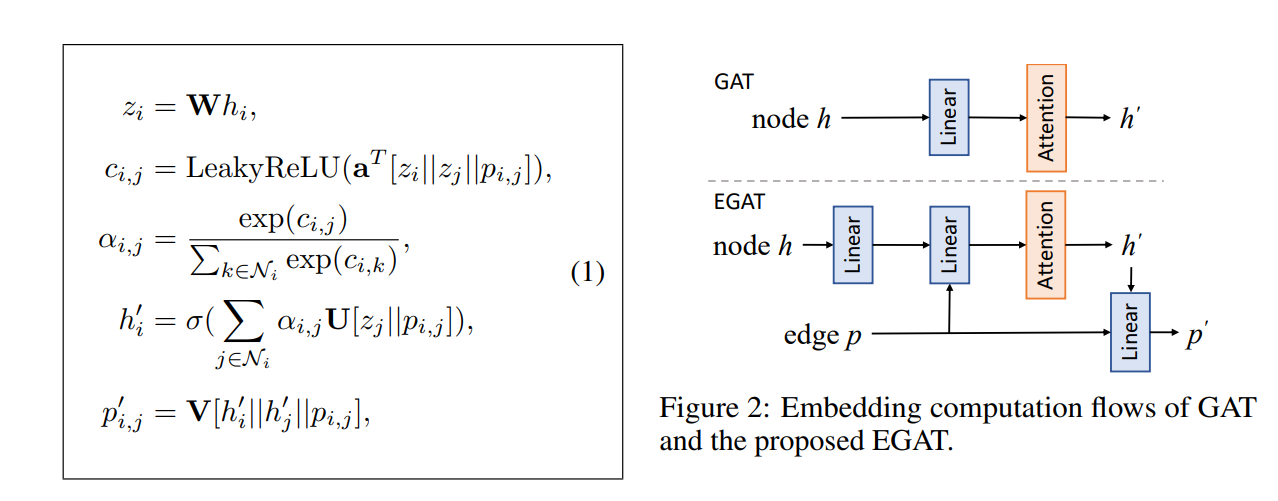
传统 GAT 模型如下图的右上部分所示,每一层的输入是每个节点(即原子)的特征,经过一个线形层和一个注意力层得到隐藏层特征,本文增加了“边”的概念,如右下角所示,每个节点经过线性层后(h->z)会和相邻节点以及边特征进行拼接(z+p->c->a)以计算注意力。因此可以理解为 EGAT 的注意力不在原子上,而在边上。然后对于每个节点,拼接不同的边再用注意力加权求和再激活得到新的节点特征。而对于新的边特征,则是拼接节点和边再过一层线性层。(比较好奇为什么边的特征不需要激活函数)。
作者使用 DGL 实现该模型,这里简单介绍下该模型的 代码,上述公式中共用到了 4 个线性层,分别是 W、a、U、V。下面代码仅仅是一个 GAT 层,和一个完整的神经网络类,包括多层多头 GAT,多头部分没有什么好研究的,和其他 GAT 差不多。
里面有一个细节笔者没有太理解,原文说断键数量如下公式,也就是 hG 经过 Ws 线性层然后是 Softmax 层,但代码里(linear_h)是线性、ReLU、线性,不知道是不是这两个可以互相代替。
1 | class GATLayer(nn.Module): |
RGN (Reactant generation network)
作者使用 Transformer 模型构建了反应物的预测,这个就和类似 Seq2Seq 这样的模型差不多,只是该模型只用以预测合成子到反应物的过程,如下图所示,模型的输入是反应类型(如果没有反应类型则用[RXN_0]表示)、产物以及断开后的两个合成子,模型输出则是目标反应物。某种意义上该模型学的不仅仅是合成子能用什么反应物代替(光是合成子理论上是无法推导到反应物的)。关于 Transformer 这里不做过多介绍,网上有很多类似的介绍,笔者比较喜欢 这篇文章 介绍了 Q、K、V 三个矩阵到底是怎么回事。作者使用 OpenNMT 实现的 Transformer 模型,应该没有网络架构上的创新,因此,只需要按照下图准备数据即可。

重现过程中踩的坑
直接从 GitHub 拷下来的代码无法跑起来,可能会和版本有关,这里记下笔者重现的方法以及碰到的问题。
版本,作者使用的是 DGL,考虑到兼容性的问题,笔者建议不要用太高的 Pytorch 版本,这里笔者使用的环境如下
1
2
3python=3.8
dgl=1.1.2.cu117
pytorch=1.13尽管 DGL 可以支持 pytorch 2 的版本,但毕竟作者使用 1 的版本建的模型,安全起见就用 1 比较好。
module ‘numpy’ has no attribute ‘bool’
这是因为 numpy 版本过高,但笔者建议既然 Numpy 团队认为要废弃 np.bool 这个用法,我们改实现代码可能要比降级更好,所以修改 preprocessing.py 中出现的 np.bool 都改成 bool 即可。
- AttributeError: module ‘networkx’ has no attribute ‘from_numpy_matrix’
这是因为 from_numpy_matrix 也已经不用,当然可以降级为 networkx 2.x 版本解决,笔者更倾向于改源码 data.py 中 nx.from_numpy_matrix 换成 nx.from_numpy_array 即可。
- ‘numpy.ndarray’ object has no attribute ‘device’
这是因为作者把 numpy array 直接传给了 DGLGraph 的成员变量,可能新版本的 DGL 要求必须传 tensor 吧。修改 data.py 中1
2
3x_graph.edata['w'] = x_bond[x_adj]
# 改成
x_graph.edata['w'] = torch.from_numpy(x_bond[x_adj])
- Cannot assign edge feature “w” on device cuda:0 to a graph on device cpu. Call DGLGraph.to() to copy the graph to the same device.
如果使用 GPU 加速则会出现这个问题,除了 tensor 外,DGL 要求 graph 也必须放入 GPU 中,所以在 train.py 中加入一行代码即可。注意有两个地方需要加入该代码,一个是 305 行左右的位置,即训练的地方,一个是 97 行左右的位置是测试的地方。
不确定这是作者忘了还是因为版本的问题,可能之前 DGL 不要求图必须也存放在 GPU 里。
1 | if not args.use_cpu: |
- view size is not compatible with input tensor’s size and stride (at least one dimension spans across two contiguous subspaces). Use .reshape(…) instead.
虽然不是很懂为什么 y_adj 不是连续的(但 x_adj 就没这个问题),只需要修改 train.py 中下面那行,增加 .contiguous() 即可
1 | bond_disconnections = list( |
参考资料
[1] https://arxiv.org/abs/2011.02893
[2] https://github.com/uta-smile/RetroXpert