QSAR 模型中应用域的定义方法
Comment使用统计学或机器学习方法构建的 QSAR(定量构效关系)模型需要定义应用域才能使模型更有意义。一来这符合 OECD 对 QSAR 的指导原则,二来从机器学习角度应用域的设定可以防止因为待测试样本的特征范围与训练集样本区别太大而导致的预测偏差过大的情况,就像用亚洲人种做的调查所构建的模型可能并不适合其他人种。从另一个角度,若通过合适的应用域可以在评估前将不适合的化合物样本踢出在外,便同样是在提高模型的准确性。当然此时也得引入另一个评价指标,即该应用域的范围有多大,我们并不希望一个模型虽然很好但仅适用于很小的化合物空间。
QSAR模型定义域主要基于化合物的理化性质、生物信息和结构特征,有三类主要的方法:距离法,标准差法以及适形预测法。
距离法
距离法即通过化合物之间的特征距离来确定待测试化合物是否属于应用域内。最常见的是 Distance to Model(DM)方法,其本质是基于训练集化合物和测试集化合物、待测的新化合物之间相似性,即通过计算训练集化合物与测试集化合物间两两相似性来确定定义域的范围。例如,对于任何一个测试集化合物,计算其与训练集中每个化合物的相似性(例如通过欧式距离表征相似性),把最相邻的 k 个分子的距离作为该化合物与训练集间的距离,然后通过训练集中化合物之间的相似性定义应用域,确定该距离的范围。当预测一个未知化合物时,通过计算该未知化合物与训练集中所有化合物间的距离,选择最近邻的 k 个化合物的距离作为该化合物与训练集化合物的相似性,当这 k 个距离中有一个超过了定义域的距离,我们就认为该化合物不处于应用域中。
$$ D_T=\overline{\gamma} + Z\sigma $$
其中,\(\overline{\gamma}\) 是模型训练集中每个分子及其最近邻居的平均欧几里得距离,σ 是所有欧式距离的标准差,Z 是超参,决定了应用域的大小,一般会取 0.5。
标准差法
标准差法本质是基于模型的预测概率,即以模型对化合物类别的预测概率值作为模型相似性的量度。例如对于二分类模型,通过该模型我们可以预测待测化合物分类的概率值,当模型预测该化合物对某一分类的预测概率大于 0.5 时,模型就认为该化合物属于那一类别。可见,当模型的预测值接近 0 或 1 时,该模型的预测不确定性越小,而当模型的预测概率值接近 0.5 时,该模型的预测不确定性越大,即模型无法很好的区分待测分子的类别。利用模型的交叉验证可以得到每个训练集分子最终得到的预测概率值,我们可以计算这些概率值的标准差,以 \(\gamma-nSTD\) 来限定模型的应用域。
$$ STD(J)=\sqrt{\frac{\sum^k_{i=1}{(y_i-\overline{y})^2}}{k-1}} $$
其中,\(\overline{y}\) 是训练集中化合物预测率的平均值,k 代表测试集中化合物的总数,以 \(\overline{y}-nSTD\) 来限定模型的应用域,n 是可人为调节的超参数。当待测分子属于某类别的概率大于 \(\overline{y}-Nstd\) 时,该分子处于应用域内,反之则不存在与应用域内。
Conformal Prediction 适形预测法
适形预测法(该翻译还有待推敲,暂根据其原理对其进行意译)也是基于分类模型的预测概率值,且基于符合独立事件的前提假设。在这个方法中,引入有效性和显著性水平 ε 的概念。若计算得到新分子类别的预测误差尽可能的小,在给定置信水平 1-ε 下不超过 ε,且如果它输出的预测类别是正确的,则认为适形预测法是有效的。
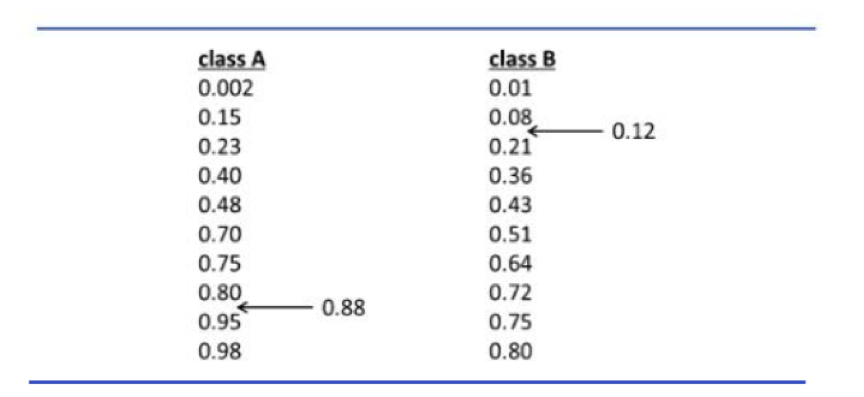
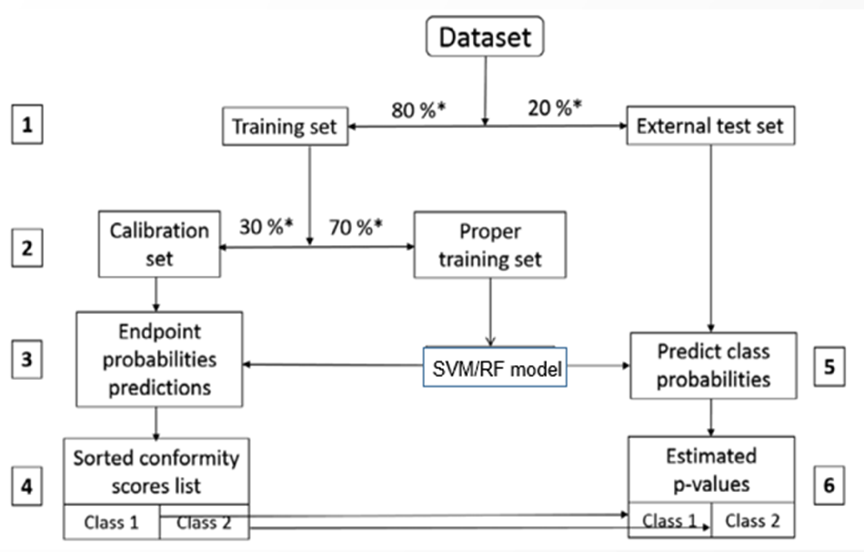
例如,在图示二分类的建模流程中,首先将数据集按照 8:2 划分为训练集和测试集,再按照 7:3 将训练集划分为建模训练集和基准集。利用建模训练集构建模型对基准集化合物进行预测,可以得到基准集每个化合物的预测概率,这个预测概率是两个值,分别是该化合物属于阳性的概率和属于阴性的概率,这两者相加为 1。将基准集中每个化合物的两个预测概率值由小到大排序,可以得到一个如图的有限的预测区域。
同样,我们对外部验证集分子也做一个预测,也可以得到两个预测概率值,分别将这两个概率值插入预测区域中,通过计算该概率在预测区域中的位置可以得到一个分数,称其为 P-value 值(该值的 P 仅仅指代 probability,和统计学中的 P-value 不是一个概念)。如图得到某一化合物属于 A 类别的概率是 0.88,属于 B 类别的概率是 0.12,可以发现该化合物的预测值在 A 类中处于第八个和第九个化合物之间,所以该化合物在 A 类的的 P-value 值为 0.8(8/10),在 B 类为 0.2(2/10)。若设定显著性水平 ε 为 0.1,那么 0.8 和 0.2 都处在这个显著性外,则认为该化合物不处于应用域中。同理,当一个化合物的 P-value 都小于这个显著性水平时,也认为该化合物不处于应用域内。而当一个化合物两个 P-value 值一个大于显著性水平,一个值小于显著性水平时,认为该化合物处于应用域内,且输出 P-value 大于显著性水平的那一类作为该化合物的最终归属。
上述方法基本都独立于机器学习方法,CP 法虽然和机器学习过程有嵌套夹杂关系,但本身仍然不参与也不利用到机器学习算法。除这些方法外还有些通过机器学习的手段进行应用域的分析,不在此文讨论范围。
本文主要由楼超峰撰写,杨弘宾负责修改。若有不足之处,欢迎指出。