波峰识别算法介绍
Comment最近的一个项目是研究钙离子信号强度的变化波形。研究方法是得到这些波的一些重要参数,比如波峰的数量、周期等。如何让计算机算法识别我们人眼一看便知的波峰则是第一个需要解决的问题。而且我们还让要让计算机知道哪些是“真正”的波峰,哪些是噪音导致的“小波”。简单的说涉及两个问题:1.波峰的本质是什么?2.真正的波和噪音的波的区别到底是什么?
波峰的本质可以从维基百科定义中得到:
波峰(英语:Wave crest)是指波在一个波长的范围内,波幅的最大值,与之相对的最小值则被称为波谷。横波突起的最高点称为波峰,陷下的最低点称为波谷。
这里有个棘手的问题,它以上帝视角看是“一个波长范围内的最大值”,而我们在解析一个波的时候,既不知道波长是多少,更不知道这段波长的范围是什么。但无论如何,它一定是一段范围内的最大值,这段范围至少得有三个点,否则不能叫“凸起”。于是我们能给出定义,一段波中,如果出现任意一点 x[i],它比 x[i-1] 大,也比 x[i+1] 大,则这个点就是波峰。其实比想象中要简单,根本不需要关心其他点大了还是小了,因为如果 x[i] 是波峰,它一定是比前后两个要大。具体算法实现部分则可以下面对 Scipy 的解读。稍微提醒一个上述描述中不完善的地方,万一 x[i]=x[i+1] 怎么办呢?算法中会有详解,这里先不讨论。
1 | 5 o o |
如上述示意图,无论是 o 还是 x 都是波峰,都满足该点比前后两个点都要大。我们也能看出来尽管 x 点可能是噪音,但无法否认某种意义上说这也是波峰,毕竟在我们定义什么是噪音之前,它们都是波峰,你说这是噪音,我也能说这不是,因此算法本身先不考虑这个问题,先把波峰都找到。
接下来讨论如何才能只得到 o 而舍去 x 呢?我开始的想法是设置高度阈值,比如最大高度的 80%,在上图中就是要 >=4,理由是只有真的峰才会很高,噪音都在下面,又比如下图是网上盗的一张核磁共振谱,我们可以设置某个强度为阈值,大于它的峰都是表示一种氢原子。
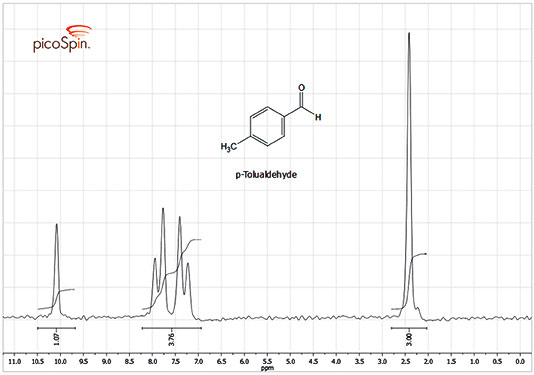
可事实并不如人愿,我拿到的波形有时可能像下面那张图一样,无论怎么设置阈值,要么就是会漏掉真正的波峰,要么就是会把噪音也加进来。

于是要靠另一个参数,prominence,即这个峰突出得有多强,我们之所以能感受到上图中哪些是真正的峰,哪些是噪音,就因为我们人眼在感知 prominence,那些真正的峰凸起有 1 以上,而那些噪音则连 0.5 都不到。因此我们需要的正是计算这些 prominence。
Prominence 大致的计算方法为:分别在 peak 的左边和右边找到一个点,称之为 left_base 和 right_base。所谓 base 就是最小值,寻找过程中满足以下这个条件:从 peak 出发,碰到比 x[peak] 还大的值时就停止,这个条件可以理解为只在这个峰附近找 ”base“,不越过更高的峰。base 也可以理解为波谷,不过需要提醒的是,由于寻找 base 过程中是可以越过较小的峰,所以 base 并非唯一的波谷,而是“不越过大峰的条件下最小的波谷”。
找到波峰和最小的波谷后,则可以通过计算两者的差得到 left_prominence 以及 right_prominence,取更小的值作为整体的 prominence。之所以取小值,是因为 prominence 指的是该峰的突出度,既然是突出度,当然得既从左边看突出多少又要从右边看突出多少,按小的算才是两边同时突出的。以第一个图为例,最后一个 x 从左边看突出度为 1,从右边看则为 2,因此我们得出最终 prominence 为 1。具体算法上如何实现,可以看下文对 scipy 的解读。
与 prominence 类似的一个常见的判断方法就是 peak_width,即波峰的宽度,默认计算波峰高度达到 50% (所谓高度即计算的 prominence)。因为往往一些重要的波的宽度可能会比较大,而噪音则宽度较小。这里就不详细介绍,有兴趣的读者可以去解读 peak_widths 函数的 源码。
最后关于 find_peaks 的用法以及详细的例子介绍则可以看 scipy 的 官方文档。
这边给出我自己的例子:1
2
3
4
5
6
7
8
9
10from scipy.signal import find_peaks
x = list('012101234543210121012345432123210')
peaks, properties = find_peaks(x, prominence=0)
print(peaks)
print(properties)
# Output
[ 2 9 16 23 29]
{'prominences': array([2., 5., 2., 5., 2.]),
'left_bases': array([ 0, 4, 14, 18, 27]),
'right_bases': array([ 4, 14, 18, 32, 32])}
Scipy 源码解读
寻找局部最大值
以下是选自 scipy/signal/_peak_finding_utils.pyx 中的 _local_maxima_1d 函数,注意这是 Cython 而不是 Python
其中一些重要的变量有:
i即横坐标位置指针,从 1 到max-1位置,因为第一个点和最后一个点不会考虑是波峰m是最终找到的波峰的数量,这个数量不会超过数据点总数的一半,因为每产生一个峰,其前面一个点一定不是波峰。left_edges、right_edges以及midpoints分别标记了每个波峰的起点、终点和中点(一般的波峰起点等于中点等于终点,但有时如上述说的“连峰”时则这三个值会不同)。i_adhead用来寻找下一个下降的点,如果下一个点和x[i]一样大则继续往后找,如果比x[i]大则说明i点不是波峰,反之如果比x[i]小则说明找到波峰了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33def _local_maxima_1d(np.float64_t[::1] x not None):
cdef:
np.intp_t[::1] midpoints, left_edges, right_edges
np.intp_t m, i, i_ahead, i_max
midpoints = np.empty(x.shape[0] // 2, dtype=np.intp)
left_edges = np.empty(x.shape[0] // 2, dtype=np.intp)
right_edges = np.empty(x.shape[0] // 2, dtype=np.intp)
m = 0
with nogil:
i = 1
i_max = x.shape[0] - 1
while i < i_max:
# 只有前面一个点比它小时才可能是峰
if x[i - 1] < x[i]:
i_ahead = i + 1
while i_ahead < i_max and x[i_ahead] == x[i]:
i_ahead += 1
# 找到下一个点比 x[i] 小,则说明 x[i] 是波峰
if x[i_ahead] < x[i]:
left_edges[m] = i
right_edges[m] = i_ahead - 1
midpoints[m] = (left_edges[m] + right_edges[m]) // 2
m += 1
# 直接从 i_head 开始考虑下个波峰,因为前面几个都一样大
i = i_ahead
i += 1
midpoints.base.resize(m, refcheck=False)
left_edges.base.resize(m, refcheck=False)
right_edges.base.resize(m, refcheck=False)
return midpoints.base, left_edges.base, right_edges.base得到 Prominence
下文摘录 scipy 中计算 prominence 的部分源码,一些不重要的代码已经删除,同样介绍先几个重要的变量:
peak_nr,表示“第几个峰”,0 表示第一个peaks是个列表,储存每个峰的位置,用局部变量peak表示。i_min和i_max分别表示搜索范围,可以通过参数wlen控制窗口范围,默认是-1,表示所有。注意i_min和i_max本身不会考虑“不越过更大的峰”这个限制,而只是需要提前设定的“搜索窗口”。left_min和right_min,分别用来记录左边和右边的最小值。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45def _peak_prominences(np.float64_t[::1] x not None,
np.intp_t[::1] peaks not None,
np.intp_t wlen):
cdef:
np.float64_t[::1] prominences
np.intp_t[::1] left_bases, right_bases
np.float64_t left_min, right_min
np.intp_t peak_nr, peak, i_min, i_max, i
np.uint8_t show_warning
show_warning = False
prominences = np.empty(peaks.shape[0], dtype=np.float64)
left_bases = np.empty(peaks.shape[0], dtype=np.intp)
right_bases = np.empty(peaks.shape[0], dtype=np.intp)
with nogil:
for peak_nr in range(peaks.shape[0]):
peak = peaks[peak_nr]
i_min = 0
i_max = x.shape[0] - 1
if 2 <= wlen:
# 如果设置了 wlen,则两边更占一般限制搜索范围
i_min = max(peak - wlen // 2, i_min)
i_max = min(peak + wlen // 2, i_max)
# peak 的左边即[i_min, peak] 范围内寻找 left_base
i = left_bases[peak_nr] = peak
left_min = x[peak]
while i_min <= i and x[i] <= x[peak]:
if x[i] < left_min:
left_min = x[i]
left_bases[peak_nr] = i
i -= 1
# peak 的右边即 [peak, i_max] 范围内寻找 right _base
i = right_bases[peak_nr] = peak
right_min = x[peak]
while i <= i_max and x[i] <= x[peak]:
if x[i] < right_min:
right_min = x[i]
right_bases[peak_nr] = i
i += 1
# prominence 等于 peak 对应的值减去左右两边最小值之间较大的那个值
prominences[peak_nr] = x[peak] - max(left_min, right_min)
return prominences.base, left_bases.base, right_bases.base